
Friday, November 24, 2006
Thursday, November 16, 2006
MP4 As The Next Popular Music Format?
 In a sense, it already is. Apple's iTunes uses it as "m4a" files. But what exactly is it?
In a sense, it already is. Apple's iTunes uses it as "m4a" files. But what exactly is it?Mp4 is MPEG Part 14, an ISO standard for multimedia compression, authoring, and delivery. Released in 2000, it is steadily catching on as a preferred format for audio (based on AAC) and video. It uses the *.mp4 file extension, although numerous other extensions that support the standard are available - such as *.m4a (audio), *.m4b (podcast, audio books), *.3g* (3G mobile devices).
The mp4 standard was originally based on Apple's Quicktime format, but was later standardized to make it more versatile and non-proprietary. Microsoft still doesn't fully support it in their Media Player application (except for video, for which you must use 3rd party codecs e.g. Ligos LSX-MPEG or EnvivioTV). The big attraction with this format is how much more it can handle - 3D objects and sprites, for example. It can also be better streamed over the internet.
But why has adoption of this format been slow? Content restrictions (copyright/DRM issues) are largely to blame. But also, although it is an open standard, manufacturers of devices and software must pay license fees because mp4 is a patented technology.
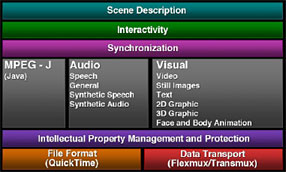
This image shows the layers of an mp4 file. I've noticed in the past that files downloaded from iTunes embedded personal information in the music file, such that if you sent the file to someone, they'd be prompted to enter your password in order to play it. Well, all that information is stored in the Intellectual Property Management and Protection layer. Software that rips music knows how to manipulate this layer, and can successfully wipe the data embedded there to make music playable anywhere. In this day and age, it sucks that when you buy music from the iTunes store, it only plays in iTunes and the iPod. I think we should be more liberal to play music we have bought anywhere so that if iTunes sucks, I can move my music to the Zune and be happy.
Thursday, November 09, 2006
Life: My Own Background Check
 A search for an ex-friend's last known address brought about the idea to do a background check on myself and see what people get when they do one on me. People meaning apartment owners, employers, creditors (banks), and non-profits that I have partnered with (mostly that deal with children).
A search for an ex-friend's last known address brought about the idea to do a background check on myself and see what people get when they do one on me. People meaning apartment owners, employers, creditors (banks), and non-profits that I have partnered with (mostly that deal with children).Some observations:
- So many variations on my names, including unknown initials and bad spellings. One report actually had my nickname, which I use when filling out non-essential web stuff. Web sharing of personal information?
- Most addresses I've lived at are correct (missing apartment numbers and such on a few). I had a couple of unknown addresses though - one in Texas and another in Virginia - both places I have never lived or been! Identity theft?
- Birthdates that make me anything from 20 years old to 53! I don't even know how to explain that.
- One record (for which I paid $10) had the last 4 digits of my SSN. Now we are in trouble.
- My credit report shows collections companies and government agencies requesting my credit. Since I have no debt, I have no idea why debt collectors would be looking at my credit. The government agency deal is understandable - I applied for a job a while back that require clearance.
- One report attempted to figure out who my relatives are. Weird variations of my last name showed up, none of which is anyone I know. Good luck with that, data-mining tool.
- Another report has me on the board of directors for a religious NGO operating in Uganda. I can see the relation, but I know nothing about it.
- Not exactly up to date - almost all report were about 6-10 months old. So if someone moved quite often, some items may never show up [private investigator tip].
- Schools and places of employment are also hinted at (names only). Are you getting scared yet?
I've got to enter the witness protection program ... I felt pretty vulnerable by how much the web knows about me, for cheap. Hack it.
Wednesday, November 08, 2006
Work: Patent Review Done, Now Filing
 Totally a highlight of the day: my patent application review process is complete (Legal Department level) and a filing has been initiated! In the memo, all the important people now officially know, including my managers, the VPs, and HR. The first paycheck next month will include a monetary award, but also the paperwork and clarification process increase in volume.
Totally a highlight of the day: my patent application review process is complete (Legal Department level) and a filing has been initiated! In the memo, all the important people now officially know, including my managers, the VPs, and HR. The first paycheck next month will include a monetary award, but also the paperwork and clarification process increase in volume.It's been an interesting process so far, mainly teaching me the value of writing exactly what I mean/what is (technical details paramount), doing demos for whoever would ask, learning the ISO/IEEE processes of documentation, and basically growing professionally. Although I don't have a college degree [yet], a patent will indeed look good on my resume!
This patent is at the core of my Jaspora invention - a web-based workflow system used to gather (sometimes with automation), analyze, store/process, and report quality analysis/software test data. We've been using Jaspora at our company for a year now - total proof of concept.
This is excitement ...
Monday, November 06, 2006
PHP: A Primer And New Project
For the next few weeks, I will be dipping my toes in the world of PHP scripting and the MySQL database application. The application slated to replace Jaspora uses these technologies, and it's important that I become very familiar with them at this point. As a matter of common practice, I develop a real-world application while learning a new technologies - real hands-on. For this endeavor, I'll create a web-based application that keeps track of my projects, like my own personal SourceForge. It'll integrate Jaspora, my personal music site, and provide a portal for private projects I work on for Strive!. Should be simple enough, I suppose.
What you need to get rolling:
If you have programmed before, learning PHP is a simple affair of learning language rules. I'm working out of the reference "PHP and MySQL for Dymanic Web Sites". Pretty simple book for beginners.
What you need to get rolling:
- A PHP interpreter. The Windows version provides DLLs that can be referenced by the web server in order to interprete .php file scripts. Without it, the web server thinks the files are simple text files and may show them as such (in Firefox. IE just doesn't show anything inside tags it doesn't recognize). [version 5.2.0].
- A web server - to dish out pages and content when requested from users' browsers. There are several free web server engines, but I chose to go with Apache's HTTPd - simple server that can run as a service on your Windows machine. I was surprised though that I could have chosen to use IIS (not a fan). [version 2.2.3].
- An SQL database application - certainly MySQL, although I could have dumped this experiment to my network of Microsoft SQL 2000 machines. From brief research, MySQL is actually enterprise grade ... and is one of the most popular databases on the web. [version 5.0].
- An intelligent PHP script editor. You could use Notepad if you want, but anyone that's used an IDE knows the value of keyword highlighting, debugging, code completion, etc. I found a free one at MPSoftware's website called PHP Designer 2007. Better than plain text for sure.
If you have programmed before, learning PHP is a simple affair of learning language rules. I'm working out of the reference "PHP and MySQL for Dymanic Web Sites". Pretty simple book for beginners.
Thursday, November 02, 2006
RE: The Compile Process
Creating a program involves writing [source] code and 'compiling' it into an executable program. This is a programmer's job, in a nutshell, but a lot goes into this process than may be suggested by the previous statement. To be good at software reverse engineering, you must understand how programs are made to be able to disassemble them properly.
For most programs, programmers use a development environment (IDE) to develop code in a language of their choice. My favorite IDEs include Dev-C++ (for C++ development, uses the gcc compiler), Eclipse/JBuilder/Sun Studio/NetBeans (for Java development). IDEs contain tools that convert high-level source code to machine-native instructions.
To build a program, two processes happen: compiling and linking. Compiling involves resolving syntax errors and creating object files. Linking involves using the object files to create a single executable file. In more detail the process in much more involved: from source code -> preprocessing -> parsing -> translation -> assembly -> linking -> loading. The process is mostly the same whether you compile on Windows or Unix - tools may differ. For example, gcc vs. cl.exe (compiler, parser, translator), or as vs. masm.exe (assembers), or ld/collect2 vs. link.exe (linkers). Microsoft compilers may additionally require .lib or .def files in addition to .dll files when linking though.
Interpreted programs like Java or Visual Basic ones are easier to disassemble because everything is initially compiled into bytecodes (for Java). For Java, the runtime environment (JRE) takes care of verifying bytecode, loading classes, and JIT-compiling before executing the resulting native code.
My focus will initially be on reverse-engineering Java programs since I am already a Java programmer. I'd like to work on larger programs thereafter, iTunes on top of my list.
For most programs, programmers use a development environment (IDE) to develop code in a language of their choice. My favorite IDEs include Dev-C++ (for C++ development, uses the gcc compiler), Eclipse/JBuilder/Sun Studio/NetBeans (for Java development). IDEs contain tools that convert high-level source code to machine-native instructions.
To build a program, two processes happen: compiling and linking. Compiling involves resolving syntax errors and creating object files. Linking involves using the object files to create a single executable file. In more detail the process in much more involved: from source code -> preprocessing -> parsing -> translation -> assembly -> linking -> loading. The process is mostly the same whether you compile on Windows or Unix - tools may differ. For example, gcc vs. cl.exe (compiler, parser, translator), or as vs. masm.exe (assembers), or ld/collect2 vs. link.exe (linkers). Microsoft compilers may additionally require .lib or .def files in addition to .dll files when linking though.
Interpreted programs like Java or Visual Basic ones are easier to disassemble because everything is initially compiled into bytecodes (for Java). For Java, the runtime environment (JRE) takes care of verifying bytecode, loading classes, and JIT-compiling before executing the resulting native code.
My focus will initially be on reverse-engineering Java programs since I am already a Java programmer. I'd like to work on larger programs thereafter, iTunes on top of my list.
Subscribe to:
Comments (Atom)